 ���ں�
���ں���Ϊ��֧�л����Ƴ�����Ƹ����ֲܷ�ʽ���ݿ�
2018-07-09 10:57:18
- +1 ������
7��6�գ�2018 ArchSummit ȫ��ܹ�ʦ���������������Ļ���ⳡ�����˰���λ�����⼼��ר�����ݽ��α��ļ������飬�����Ը��и�ҵ�ĸ߶˼��������ߡ��ܹ�ʦչʾ���Ƚ���������ҵ�е����ʵ�����Լ���������ҵת�ͷ�չ�е��ƶ����á�

��Ϊ�Ƽ���ר�ҽ�������Ƴ����ܹ���Ƶķֲ�ʽ���ݿ�
����ʱ������ҵ IT ҵ������������ȫ����IT Ӧ���������ƻ����ֲ�ʽ�������ݿ���Ϊ������ҵҵ���Ӧ�õ����ģ��߱�������ֲ�ʽ�������������������ԡ�Ҳ��ˣ���Ϊ�Ƽ���ר�Ҵ����������ݽ��������Ƴ����ܹ���Ƶķֲ�ʽ���ݿ⡷���ܺ�����
һ�ж����������ƶˣ��õļܹ��ǰ������кü�������Ҫǰ�ᡣ�����ݽ������ܽ��˴�ͳ���ݿ����ƻ��Ʒ��������������⣬������������˻�Ϊ��ԭ���ֲ�ʽ���ݿ�ļ���ԭ�������ʵ�������ڶ�λ��߹�ͬ̽���������ݿ�����ʱ�ڵ�ʹ�úͷ�չ����
��ͳ�ܹ��µġ����ݹµ���
��ͳ���ݿ�ܹ�Դ�� 30 ����ǰ��Ӳ����ƣ�Ӳ����ʹ�õ���������С�ڴ������ٴ��̣������ϲ���˫���ȱ��ṩ�߿���(HA)������ζ������������в�����������־���ӿ�ӿ���ط���־���±������ݸ�������ˣ����ݿⷢ������崻�����Ҫ�����л�ʱϵͳ�����������ٲá�������ʵ�����������־����������͵Ļ�����ҵ��߲����������ԣ�������Լ�����ݿ����ԺͿɿ��ԡ�
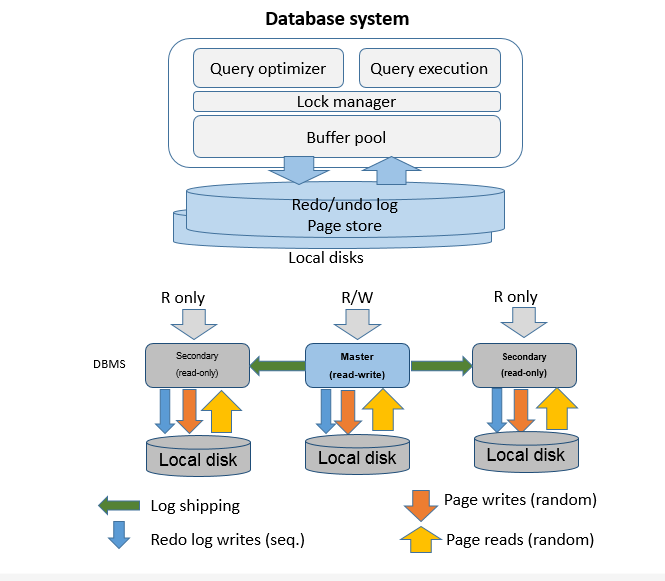
��ͳ���ݿ�ܹ�
��ǰ���й��� 70% ������ҵ��ҵ����������ս����Ӱ�죬�����ٵ���Ҫ��������˸߳ɱ��͵�Ч�ʡ������ݡ���ը��Ӱ�죬������ҵ��������µ�һ��ɢ��ָ��ڸ��������ݱ��ݡ������ھ�������Ų���Ҫ������Դ����ҵ����������ҵ license ��רҵ����ʦ�߰��ķ��ã���˴洢��ת�ơ�������ʹ����Щ���ݷdz����ѡ�
�ڴ˱����£��߿��á�������ά������չ�������ܡ���������ศ��ɵ������ݿ⣬�����ǻ����Ƴ����ܹ���Ƶ���ԭ���ֲ�ʽ���ݿ⣬��Ϊ��ҵ�������ѡ�����м�����洢���롢�ܳ�ַ�������Ӳ�����ܡ����� AI �� ML(���ѧϰ) �ȹ��ܳɷ�չ���ơ�
Gartner ������ʾ����2019�꣬90% �������ݿ�ܹ����ü�����洢����, ʣ��10%û�з���ģ�Ҳ�ᱻ�г�����̭�����⣬ NUMA �ܹ��Ķ�� CPU��Optane SSDs �洢��RDMA ���硢GPU/ FPGA ר��Ӳ��������Ӳ��������Ҳ�ܱ��¼ܹ��µ������ݿ����գ�������˹����ܺ����ѧϰ�ӿ�����������
��ԭ���ֲ�ʽ���ݿ⼼��ԭ��
ֵ��һ����ǣ���Ϊ�Ƶ����� 30 ����ļ������ۣ��Ѿ������һ������ԭ�����ݿ����������Ի�Ϊ���Ƴ��ĸ�������ԭ���ֲ�ʽ���ݿ�Ϊ������������ǻ�����Ӳ�����ܣ�Χ�ƽ�������ݼ�������(NDP)������ AI �� ML �ȹ�������չ����
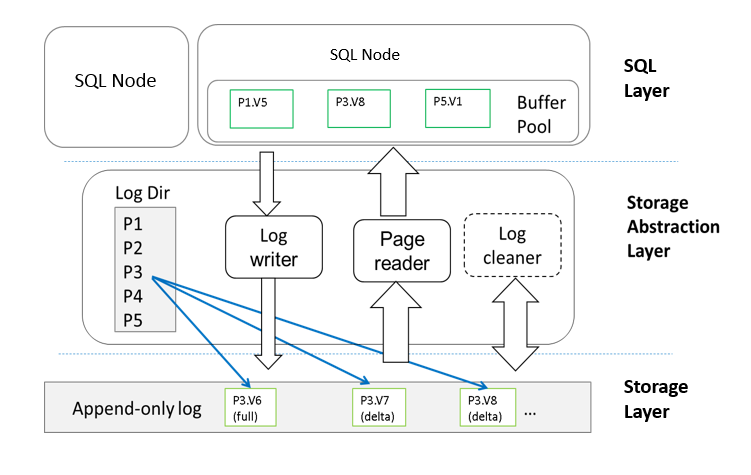
��Ϊ��ԭ���ֲ�ʽ���ݿ�ܹ�
��Ϊ��ԭ���ֲ�ʽ���ݿ⽫ʵ�ּ�����洢���롢���ӽ���;��IO �ܼ��������Ƶ��洢�ڵ���ɣ����� redo ������ҳ�ع�;���⻧֧��;���� AI �� ML ��������ϵͳ����չ���Ե��ŵȹ��ܡ�
��Ϊ��ԭ���ֲ�ʽ���ݿ��������ƴ洢������,ʵ�ִ洢������ݴ�����������д����Ĺ������ʡ����� SSD ���ƣ�������� SSD ����������ܣ��������д������д�Ŵ���ĥ�𣬼�Сʱ�ӡ������� RDMA �������缼����Ӳ���������粻����ƿ�����Ӷ�ʹ�������ܵõ��ܴ�������
���⣬��Ϊ��ԭ���ֲ�ʽ���ݿӵ�м������á��������������ɹ���������ʵ�õ��ص㣬�������û����ù��ĵײ�ܹ��ͻ�����ά��ֻרעҵ��չ�����뷢չ�Ƽ��㼼������Ҫ��Ŀ�IJ�ı���ϡ�
���й�ͨ��Ժ���Ѿ�ʹ�ú��мƻ�ʹ���Ƽ��㼼������ҵ�����У�67.81% �Ĺ�˾��Ϊ����Ӧ�ò���ʱ����Ӧ���Ƽ�������ҪĿ�ģ�62.56% �Ĺ�˾��Ϊ��Լ�ɱ���Ӧ���Ƽ��㼼������ҪĿ�ġ�

������Դ���й���Ϣͨ���о�Ժ
�����������ԣ��м�ֵ�Ķ���ֻ�жԶ��õ��˲������壬��һ�������ļ�ֵ�������Ƿ���Ҫ��������������ʻ�Ϊ��ԭ���ֲ�ʽ���ݿ��ܸ��û�����ʲô����ô�Ƽ���ˮ��ͷ�۵��۸պÿ��Իش�������⡣������Ҫ��ʱ��ֻ��Ť��ˮ��ͷ��ˮ�����ˡ���ֻ��Ҫ����ˮ�ѣ�������Ҫ����ˮ��!





������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼



























