 ���ں�
���ں�ȫ������������崻��¹� ���������ҵ�����˱���һ�Ρ�
2019-03-04 14:53:18
- +1 ������
һ���¹ʣ������й����Ĺ����Ƴ����������۷籩�����ġ�
3��2����ҹ��������ͻȻ���ֹ��ϣ������ڶ������²ۡ��й�˾����ָ������Ϊ�����ƻ���2�����������쳣�����ºܶ������˾��App����վ����̱����һ����Ա����Ӫ����άרԱ��ȥ��˾�Ӱࡣ
֮�����ƵĹٷ���Ӧ�ǡ�����2���������C����ECSʵ��״̬�쳣�����¸������ڶ���վ��App��������ʹ�á���
3��3�գ������Ʒ������棬����˵������2���������C����ECS��������ʵ������IO HANG���������Ų鴦������ȫ���ָ���Ŀǰ��������ȫ���Ų���������������δ���ִ����������Ա��ι��ϣ����ǽ�����SLAЭ�飬����ش����⳥���ˡ���
�����DZ���崻��¼��Ĵ��¾�����

���������������ƹ��棬�����кܶ����ʣ���εĹ���ԭ����ʲô�������Ƶ���С��ҵ��˵���Ժ���α����Լ��ķ����Լ������⳥��ν��У�
���ֻ��һ����վ崻��ˣ������������վ���û�����¼��ʹ�ã�������Ϊ�������Ĺ����Ƴ��̣������Ƶ����崻���ȴ�����������˾��App����վ̱����
��������ʾ���й�Ŀǰ��40%����վ�����ڰ������ϡ���Ϊ�������Ĺ����Ƴ��̣�������ռ���й�45%���Ƽ����г��ݶ˵�ø���������һ�������⣬��ֱ����һ������ҵ��
��ɰ����ƹ��ϵ�IO HANG��ʲô��
����ע����˴��¼�������Ҫ�㣺һ�ǰ�����崻���ԭ����IO HANG�����ǰ����ƽ�����SLAЭ�飬�����⳥��
����˵˵IO HANG�������ȥ�ٶ�������������ȫ�ǰ�����崻�����û�й���IO HANG�ľ�����͡�
��֪������������(���������и߲㡱�ĵײ�ܹ�ʦ)���ͣ�IO HANG����˼�����IO�����Ƕ������ˣ���IO�������IO·�������������ڲ����ݿ����쳣������

����һƪ�����̵���IO hang������������£���ָ�������ֿ��������
һ���dz��ֻ��̹�����raid������Ϊ�����쳣������̨�����ϵ�ִ��raid��������megacli����ס���۲쵽��̨�����ϵ������̵�io��ʱ��ʱ�쳣��æ(io������svctm�����ﵽ��ǧms)���Ӷ��������ǵĿ�洢�ľ�IO hangס�����־����û��ľ�io util 100%�ϳ�ʱ�䡣
����һ������ǻ��̺����̴�raid������(���ĵ���raid0��Ĭ��WB������ԣ��̻�����Ҫ��raid����ɾ������)����̨�����ϵ������̶�io��סһ�ᣬ����megacli����Ҳ��ס���Ӷ�Ҳ���²����û��ľ�io util 100%�ϳ�ʱ�䡣
ʵ���ϣ��Ⲣ���ǰ����Ƶ�һ�γ������������
2016��10��11�գ������ƻ�����������ECS����������IO HANG���⣬���²�����վ̱����һЩ�û��������Ʒ��������ڶ��գ�������ͨ����������������ECS�������������⡣
֪������Ϊbaiy.cn���������۵����������Ƶ�IO HANG�Ǹ���BUG����Ϊ������ԶHANG���ǣ�������IO Timeout���⼴���㼴ʹ���˿�IDC�ĸ߿�����ƣ�Ҳ����ʵ�ֹ���ת��(Failover)�ȶ������൱�ڰ�һ�и߿��üܹ��������ˡ���
��λ���ѽ�һ������˵����������ȫΥ�������洢�豸(�磺���̡�RAID����SAN��)����Ϊ�����˻������д�����IO��������Ʒ(�磺MySQL��MongoDB��SQL Server��)�ĸ߿��ü�Ⱥ������������������
���Ʒ���ר�ұ�ʾ�������������TOP�����ϣ��������ƴ��̶�д�IJ�����ס�����ˡ��������ݿⶼ�ڴ�������ֿ��ټ�����������������û�Ӱ��dz���
2015��6�£��������������������������跽����Ӫ�̵������������ۻ������ϣ��ϵ�12Сʱ;
2015��9�£��������ƶٵİ���ʿ��Ʒ����������bug�����û�ECS�еIJ��������ļ�������;
2016��7�£������Ʊ������������������ϣ����´�����������˾ҵ���ܵ�Ӱ��;
2016��12�£������������������ֹ��ϣ��ٷ��ƹ���ԭ��Ϊͻ���������������µIJ��ֽ����������쳣����
������ҵѧ���ı���һ�Σ����߿����� ������
�Խ������ҵ��˵��������һ�����ƣ��������ֻ�ת�͵ı���֮·�����ǿ�������AWS����Azure�������Ƶȣ�ȫ���κ�һ���Ʒ����̶Է���ɿ��Եij�ŵ������100%��Ҳ������100%��
����ζ�ţ��Ʒ����ṩ���ܻ����һЩ���ɱ�������⣬������Ȼ�ֺ����̨�硢���ꡢ����ȣ���Ϊ����ɾ��������ȡ���Щ����ķ�����������������ҵ�ķ����ܵ�Ӱ�죬����崻��ȡ�
���ڵĹؼ������ǣ�����С��ҵ��˵�����������֮����õ�ʵ�����ұ��ϣ�

�Դ���ҵ��˵���г�����ʽ�֧�֣���ҵ��ITϵͳ����ñȽϺã����DZȽ���ȫ�����Ƕ�һЩ��С��ҵ���ԣ������������ʧ���ء�
֪������Ϊ���۵�����˵�ñȽ����У�����������������Ƚ����Σ������Ƕ���С��ҵ�����ڰ������ϣ���������һ�����Ǹ��������������л��������Ƶ�ʱ���Խ��ĸ��������������Ӫ���ĸ����йҵ���ʱ��
������˵��Ҫ���ƣ���ʵ�Լ��ܹ������Ķ�֪��������̫�࣬������ͷҪô��DDOS�ˣ��õ�ʱ�䳤�Ļ���Ӳ�����ˣ����ݶ�ʧ��ʲô�¶����У�����ȷʵ����˲������⡣����д����
������ҵҪ�����ǣ����Ʒ����ṩ���ṩ�ı����ϣ��ټ�һ������֡�
������漰�����֡����һ�ҹ�˾����ôһ̨������֧���������һ���������⣬��û�п������߿����ԣ���ô��ҹ�˾��ҵ������ˡ�
֪��������������˵��������¹ʣ���������ͬ�����֣�����2��C�������ˣ����ٻ���2����A��B���������������ݡ�����Ǹ���Ǯ��һЩ��˾�������������ֲ��ԣ������Ͽ��Աܹ��Ƴ������е������¹��ˡ���
��ҵֻҪ���������������ͬ��ITϵͳ������֮����н���״̬���Ӻ����л�����һ��ϵͳ������ֹͣ����ʱ������Ӧ��ϵͳ�Ϳ����л�����һ����ʹ�ø�ϵͳ���ܿ��Լ�������������
����ҵ��˵������ʱ��IJ��Ϸ�չ��ҵ�����ӻ�䶯��ITϵͳҲҪ�仯��Ϊ��ʵ�ָ߿����ԣ�������һ���dz���Ҫ�����飬���Ա�֤��˾ҵ����ȶ���������ǰ��չ��
�ⲻ֪����Щ��������˾��һ��崻�������ʧ���أ������û���ʧ��ҵ�������ش��������š�����ν��δ����ѡ������ܡ��б�����!
������⳥���⳥�ǰ��չ涨���ģ����ݾ��ǰ�������ͻ���ŵ��SLA����ȼ�Э�顣���ݰ����ƶԷ�������Եij�ŵ��
1. ���ڵ�ʵ��ά�ȣ������Ƴ�ŵһ������������ECS�ķ�������Բ�����99.95%;
2. ���ڵ�����������ά�ȣ������Ƴ�ŵһ������������ECS�ķ�������Բ�����99.99%��
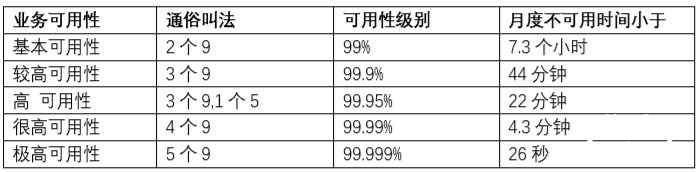
��Ȼ�������⳥��һ�а�������������ɡ�
��
��������˵���ⲻ�ǵ�һ�ι��ϣ�Ҳ���������һ�ι��ϡ��������Ʒ����ṩ�̶��ԣ������Ʒ����Ĺ���Ҳ�����Լ����ϲ������ݡ�����������ҵ��˵�����¹ʡ���һ�δη������ϵؽ�ѵ���Լ������Ʋ���ȫ���Ʒ����ṩ�̣��Լ�Ҫ����ITϵͳ�ĸ߿����ԣ�Ҫ���������֡�
������������Ϊ�켫������ԭ�����ݣ�δ����������ֹת�ء���






�ǰ���
������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼



























