 ���ں�
���ں���ɽ�ƿƼ�CTOͯ��:���ܷ�����ϵ����֮·
2016-10-24 13:11:00
- +1 ������
10��22�գ���ά������������������ṩ�̰�ɽ�ƿƼ�����˾(���¼�ơ���ɽ��)���Ͼٰ조����Ϊ��������ɳ������ɽ���ϴ�ʼ�˼�CTOͯ������˿������������˺��±���MySQL��ά�Զ���ƽ̨��������ΰ����������վ���ܼ�⡢�������Ż�����������һͬ̽����ν���ȫ�桢��ʱ�����ܼ���������ϵ��������Ӧ������վ���������Ż���

��ɽ�ƿƼ����ϴ�ʼ�˼�CTO ͯ��
ͯ���ڼ��˰�ɽǰ�������˹���16�꣬�����з��Ķ�̬Ӧ��ƽ̨�����ݿ�ƽ̨��ʹ��������ʵ�ּ���ƽ̨ͳһ��֧�������ı���ʽ��չ;���쵼�Ƴ���������һ�������ơ���SAE��ƾ�������з���������飬ͯ���������Ż������γ���һ�������⣬���ֳ������з�ͬѧ���������վ�ڸ��ߵ��ӽ�ȥ�˽����ܡ�
һ���ڸ����ӽǽ������ܹ�����ά��ϵ
(һ) ���ܹ�����״
Ŀǰ�����ܹ�����Ҫ�����������⣺ ������Ա��עϵͳ����ĸ�������ָ��ͼ�أ��Կͻ����������Ӳ���;ҵ���뼼�������ܱ����ڲ��죬ϵͳ���úò������û������;����֧�ֲ�Ʒ��������Ӫ����������������ڿ���;û������ָ��仯�����ⶨλ�Ķ�Ӧ��ϵ��ָ�������쳣��ȴ���Զ�λ��������;ȱ����ϵ��������û��ͳһ������ָ�����Ӫ�������Լ����϶��µ�Э����ϣ��������������������Ľ���
(��)��ص��ڲ���ɫ
�������ⲻ���뼼����Ա��أ���˾�ڲ���������ԱҲ���Ӧ�����ܲ���ֱ�ӻ��ӵ�Ӱ�졣ҵ���ܸ����ˣ���������Ŀ����ҪӰ����;�������������������ճ��������������ⷢ�ֺͷ������ƽ����; ��ά��ͷ���Ա���ռ��ͷ����û��������������⣬����������ƶ���֮һ;��Ʒ��Ա�������Ʒ�Ľ���������ƺ��������ڣ���������������ȼ��жϽ�������Ľ������ֱ��Ӱ��;������Ա���ͻ��ˡ���˼�����������ϵ�Ŀ���ʵ���ߣ�������������Ҫ��ֱ�ӵ�Ӱ�����ء�
(��)����������Ӫ����
���ܷ������߽��裬��������������ָ����ϵ���������ݲɼ���������������ȷ��;�����ռ��������ƣ�ͨ��Ա�����ͷ�����ữý���ռ��û��������⣬ͳһ���ٴ���;���ܹ�����Ӫ���ƣ���רְ��������������������Ӫ�������������Ⲣ�ƶ�������ؼ�������ָ��ֽ��ҵ��������;�ƶ�Ŀ�ꡢ�ֹ�������������Ҫ�����٣��ƶ�ÿ���ε���������Ŀ�����Ҫ������������⣬�ֽ��������˺��Ŷӣ����쵼�ƶ����������
(��)�ؼ�ָ�궨��
����Ӧ�����ܹ������ƣ�������Ҫ����Ӧ��������Ҫ���û��������鶨������������ܹؼ�ָ�꼰���㷽�����ؼ�ָ����Ҫ���Է�Ϊ���¼��ࣺ
1. �ٶ��ࣺ����Ӧ�õ�������Ӧʱ�ӡ��ļ������ϴ��ٶȡ�ͼƬ����Ƶ�����ٶ�;
2. �����ࣺ����Ӧ�õijɹ��ʡ������ʡ�������ij����λ�İٷֱ�;
3. �����ࣺ������Դ�����ʺͷ���������������ÿ����������������CPU�����ʡ�
���Ϲؼ�ָ�����Ԥ��ֵ�������ܵ��ڸ�Ԥ��ֵʱ������Ҫ�����ж�������ͬʱ���ǻ���Ҫ֪����ͬ�IJ�Ʒ����ҵ�����ͣ���������ܺ������Ĺؼ�ָ����ܲ���ܴ����磺��Ƶ����֡����ʱ���������ȡ�������;���������б�ҳ����ʱ������Ʒҳ����ʱ����֧����Ӧ�ٶȡ������ʵȡ�
(��)���˹�ϵ����
��������ʱ��Ҫ����Ӧ��������ļ����ܹ����������˹�ϵ������Ҫ�ġ�

Ӧ�����˹�ϵ
��Ӧ���ձ�ļ�����ϵΪ�����������������ķ���Ԫ���ײ�����ڶ࣬ͬʱAPI����ã�����Ӧ�õ����˹�ϵ��Ϊ���ӣ����Է�Ϊ���¼����ֽ���������
1. �����������ӹ�ϵ������������3���·����Ϣ�����������������Ϣ����������������Ϣ������������֮��ͨѶ�ֱ�����Щ����ڵ㣬��Щ��Ϣ��Ҫ���;
2. Ӧ�������ĵײ�������磺���ݿ⡢CACHE���洢��;
3. Ӧ��API��ĵ��ù�ϵ��ҵ��IJ�ͬ����ģ��֮�仹��Ҫ�˴˵��ã�����API֮��ĵ��ù�ϵҲ����Ҫ��
��Щ������Ϣ�͵��ù�ϵ�ļ�¼�������Ҫ�����˹����º������´����߸��²�����ʱ�������µĵ��������Զ����ɼ����£��Զ��ɼ��������е���Ϣ��Ӧ�õ��ø��ַ������־��ͨ�������ݷ���������ѧϰ�ļ�������̬�����������˹�ϵ����ɽ�Ѿ�����Щ��������˳��ԣ���ȡ���˲����ɹ���
(��)���ά��ȫ����
�����ݲɼ������Ƕȶ�γ�ȸ��ǣ����ڸ��ӿ��پ��Ķ�λ�������⣬��Ҫ�ɼ��������ά�ȵ����ݣ�
1. ����㣺��Ҫ�ɼ������ʡ����ڴ����������˿ڴ��������ؾ�������ݣ�ͨ���IJɼ�������3-5min�����ǽ�������30s���ڣ��������ܲ���˲ʱ�������쳣����;
2. ϵͳ�㣬���������ء�����IO���ڴ���CPU������PPS������;
3. ���������㣬������Apache��Nginx��MySQL��Redis��Kafka��;
4. Ӧ����API�㣬�������������������ʡ�ƽ��ʱ�ӣ��Լ���ͬ�ȡ����»��ȵ�����;
5. �ͻ��ˣ���������Ӧʱ�����������ܡ������ʡ�������Ϣ��
(��)�ͻ������ݲɼ�
�ͻ��˵����ݲɼ�ʮ����Ҫ���ͻ��˵����ܱ��֣����ܶ�����������Ӱ���⣬�����������API����ֱ����ء����Ҫ�����Ǿ�ϸ�滮�ͻ������ݲɼ���ϵ��һ�����������ֿͻ��˵�ʵ������ɵ��������⣬��һ�����ܸ��õ������������˵����ܣ�Ϊ���������Ż��ṩ����Ϣ��
1. ��Դ���ͻ������ݲɼ��е���Ҫ���֣���ȫ�����߳�����¼�ͻ�����������˷���ĸ���������Ϣ�ͷ���״̬������API����ͼƬ������Ƶ�����;
2. �쳣���ɼ��ͻ������в������쳣������Ϣ���Լ��������˷��صĸ��ִ�����Ϣ;
3. ������Ϣ���ɼ��ͻ��˵�����������Ϣ������WIFI/4G/3G/2G�ȣ��Լ��û��Ļ�����Ϣ��
�ɼ�������ϢʱҪ����˹涨ͳһ��״̬�����룬��������ص�������ͳһ��־����ʱ���Ӷ����ӡ�
(��)��������ݲɼ�
1. WWW��־��������־���ڲ�������ͳһ��־��ʽ�淶��ҲԤ������չ�ֶ�λ����ͬҵ���Զ���ʹ��;
2. Ӧ����־��Ӧ�ô��������������Ҫ���ⲿ������ü�¼��������صĻ��ڴ���ʱ���¼��;
3. ����������־������Ϣ��������־�����ݿ��ѯ��־������־��������쳣������־��;
4. ������־��ȫ������Ĵ�����־��Ӧ�ó���Ĵ�����־��
�ɼ���־ʱ����Ҫע�⣺(1)��ʽͳһ����;(2)��¼�û�ID������ID;(3)��¼IP��ַ(�ͻ��ˡ������)��
(��)��������ƽ̨

��������ƽ̨
����ͼ�������һ�������ݲɼ����֣����ݲɼ�����鷳���ϱ���ϵ��������ץȡ���������ϱ��ȷ�ʽ;�������������ݹ�ģ�ϴ�ʱ��һ�����ĵĴ洢�ڵ�ѹ�����Ӵ�ʱ���ǽ�����÷ֲ㼶�������ռ���ϵ�������������ĵڶ��������ݾۺ���������ϴ;�洢�㳣��ļ����У�ʱ�����ݿ⡢ES���ݿ⡢HBase��HDFS;�����Ҳ���DZȽϳ���ļ���;������һ���Ǻ����ܷ����йصĹ��ܣ���ʵʱ���Ԥ����ϵͳ������������ѯ�����ӻ���������Ӫ��������(��Ϊ�¼���ƽ̨)������APIƽ̨(�����������ݹ�������ά���ߵ��ã����Բ�ѯ���⡢����״̬)��
����ʵս�����ο�
(һ)ͼƬ������ϵ
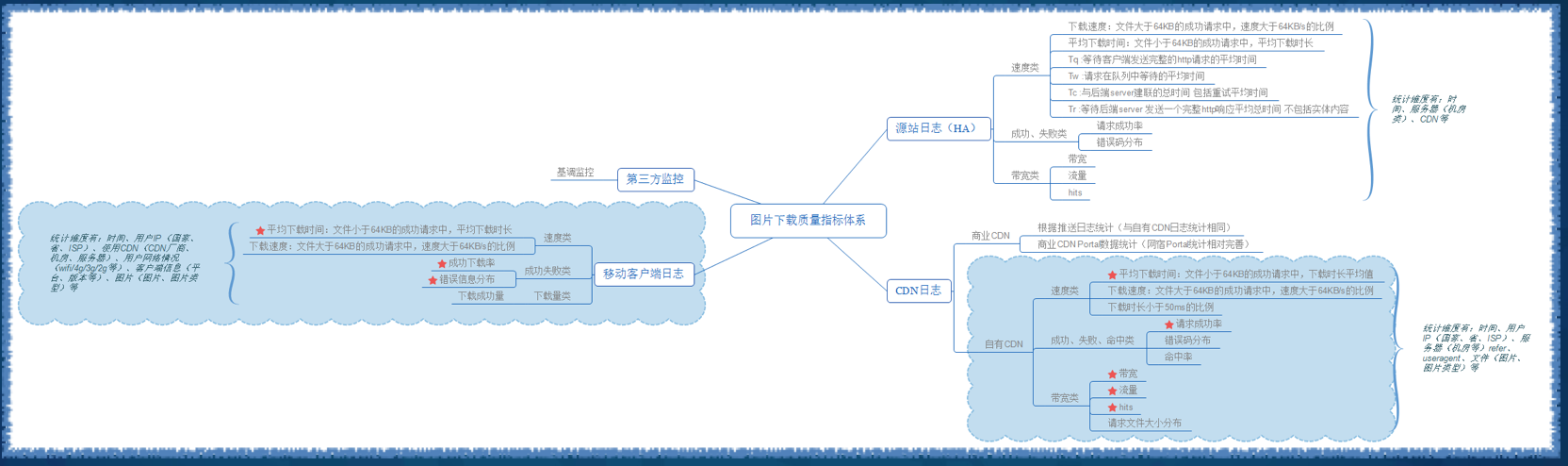
�ƶ���ͼƬ������ϵ���ݲɼ�ָ��
�ܶ�Ӧ�ö���ͼƬ��������ʾ���ܣ�������û�����Ӱ��ʮ����Ҫ��ͼƬ���ػ�����ҪӰ�����ذ�����Դվ�洢��CDN���ͻ��˼�����Ⱦ���ƣ����ͼƬ�����ܼ��Ҳ��Ҫ������3���档
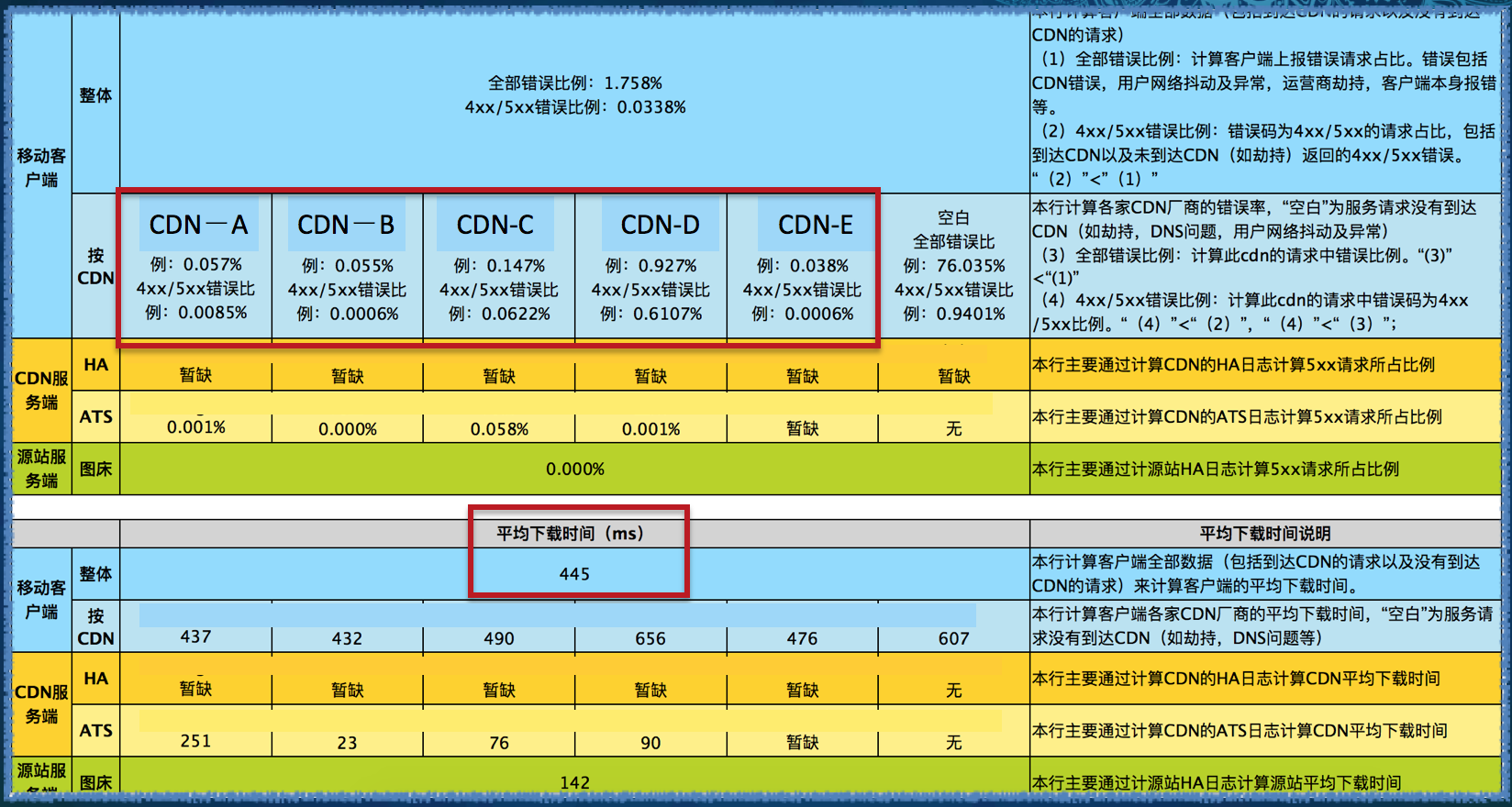
���ڲɼ��������ɵķ�������
��ͼ�ϰ벿���Ǵ�����ָ�꣬���ǿ��Էֱ��ҵ��ƶ��ͻ��ˡ�CDN��Դվ�Ĵ����ʣ�ͨ���������������ǿ��������ؿ����������ĸ����ص��µ����ܲ������ݴ˽������ⶨλ��
�°벿����ƽ������ʱ�䣬����������ƣ����ǿ��Կ������������и��Ե�ƽ������ʱ�䣬�ñ���Ŀǰֻչʾ�˲������ݣ�����ͬʱ������˸���CDN�ڲ�ͬ��Ӫ�̡���ͬ���������ݣ�����ÿ������ܽϲ�ĵ������ȸ�����CDN�۲����ܱ仯�������ܵ���Ӫ������ɳ����������������̡�
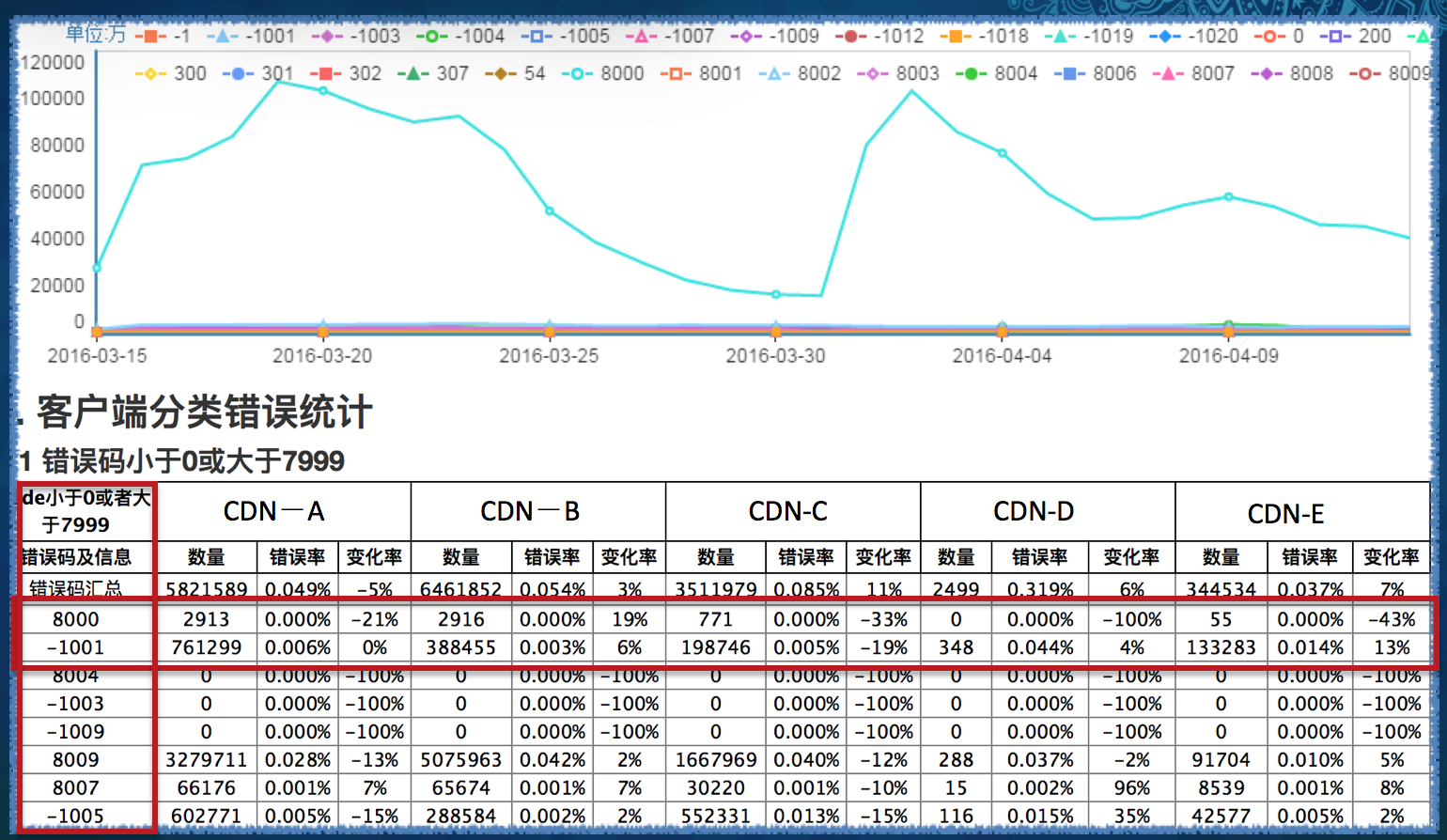
�ͻ��˷������ͳ��
�����������ҪĿ����Ϊ�˸��õķ��ֲ�Ʒ�ͼ����ϵ����⣬Ϊ�����ǽ����˸���ϸ�µķ��������������ᵽ�ģ����ǶԱ����������Լ���������մ��������ϸ�֣�ͬ����������Ҳ����Դվ��CDN��һ�����ֳ�����
(��)��Ƶ������ϵ
��Ƶ��ͼƬ���ƣ���Ҫ����Դվ�洢��CDN���ͻ����������أ�CDN��Դվ������Ҫָ������������������ʣ��ͻ��˻���Ҫ������֡����ʱ���������ȡ����ųɹ��ʵ����ء��ܶ���Ƶ��Ҫͨ��API��ȡ��Ƶ�ļ�������API�����ܡ���Ӧ�ٶȡ�ʧ���ʡ��ɹ���ҲҪ���вɼ�����;����֮�����������ߣ��Ӷ��ά�Ƚ��вɼ��������

�ײ������벥�ųɹ���
�������������⣬��Ƶ���ϴ����Ҳ�غ��û����顣
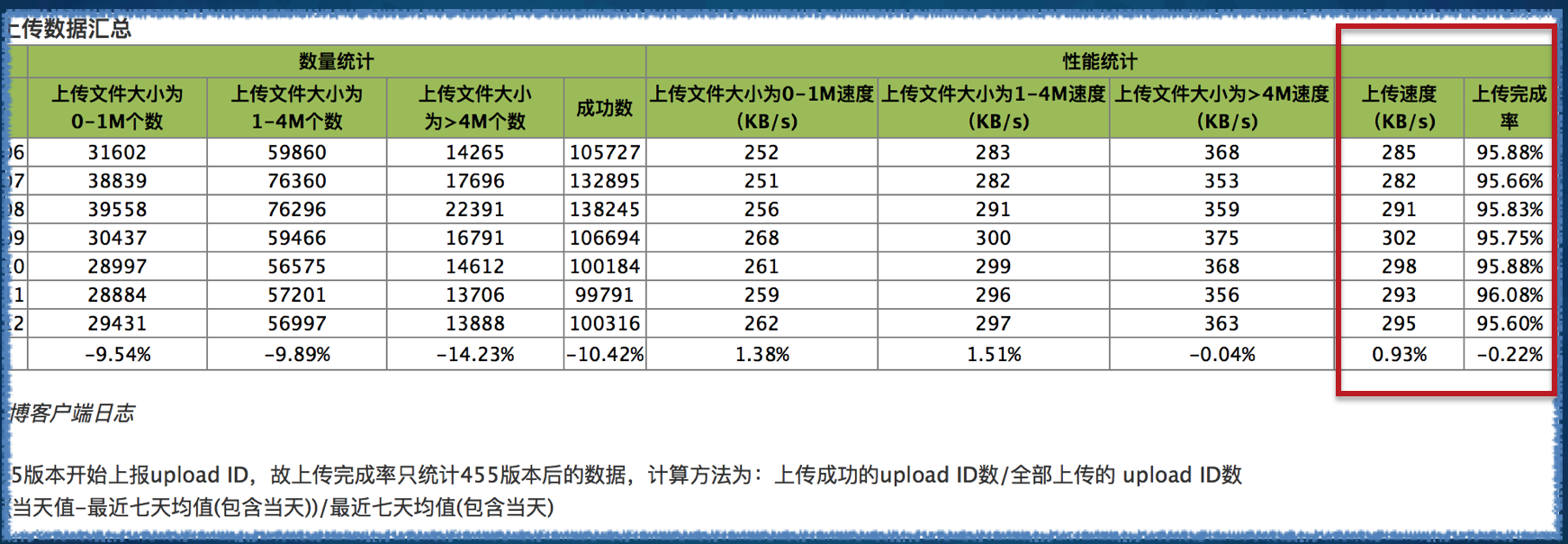
��ƵС�ļ��ϴ�
������ƵС�ļ����ϴ���������Ҫ����ϴ����ٶȺ��ϴ������������ָ�ꡣ

��Ƶ���ļ���Ƭ�ϴ�
������Ƶ���ļ����Dz��÷�Ƭ�ϴ����ƣ���Ƭ�ϲ�����������ٶ��������;��Ƶ�ϴ������ת�룬����ת����Ƚ���Ҫ��ָ����ÿ��ת���SIZE����������ƽ���Ŷ�ʱ�䡢�Ŷ�ʱ�䳬��1h���������������еȴ�ʱ�����ʱ����Ҫ���ǽ������ݡ�
(��)API���ܼ��
Ŀǰ�Ļ�����Ӧ�ã�����ӵ��2��������ƽ̨�Ŀͻ��ˣ�������IOS��Android��PC Web�汾����Щ�ͻ���ͨ��ʹ��ͬһ��API�������API�������ܹ���ʮ����Ҫ��
1. ���Ĺ���API�綨����ҵ��Ƕȳ��������ݺ��Ĺ��ܻ���Ҫ���������ҳ���ӦAPI�����ص���;
2. ��ҪAPI QPS��ʱ�ӣ�ʵʱͳ�ƺͼ����ҪAPIÿ����������ʱ�ӷֲ������������ֳɲ�ͬʱ�����䣬����500ms���ڡ�500ms-1s��1s-2s;
3. ��ҪAPI ��������ʵʱͳ�ƺͼ����ҪAPI�Ĵ�����;
4. �ײ����ļ�أ�API���������ݿ⡢���桢��Ϣ����ҲҪ����������ָ���⡣

��Ϣ��QPS��ʱ��
����ͼ��ʾ�������ڼ����ʹ�ò�ͬɫ����ʾ��ͬ���������䣺��ɫ��ʾ500ms���ڵ�������������ϣ���ⲿ����ռ����Խ��Խ�á���ҵ��߷�ʱ�Σ��������������ӣ����ǿ�������Ŀ����������Ʊ仯;ͬʱ��������ʽչʾ�ϸ�������ڵ����ݣ�����Ա�ҵ�����仯���������ơ�

������ʵʱ���
������Ҳ��Ҫ����ʵʱ��⣬���磺���ƶ��ˡ�PC�˵Ĵ�������API�˵Ĵ�����ͬʱ���бȽϣ����Խ�Ϊ�����Ĺ۲���ϵĴ���ͷ������˵Ĵ�������Խ���ʱ����������ij���汾���µ�ԭ���µĿͻ��˲��������ڽ������ⶨλ��
��֮��һ���õ�Ӧ�����Ʒ����Ҫ���dz������ϵĽ������ܼ������������ֳ���Ҫ������վ�ڸ��ߵ��ӽǽ������ܷ�����ϵ���衣






shadow
������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼



























