 ���ں�
���ں��ں����ݰ�Ƥ��:Apache CarbonData��Ϊ�����ںϴ洢����
2017-12-26 13:56:34
- +1 ������
Ϊ�˸��õ�̽���������IT������ʩ��������ܻ��ķ���չ�������������Զ������ƻ�����������ҵ��ո��δ����12��22�գ����й���Ϣͨ���о�Ժ���죬�Ƽ��㿪Դ��ҵ���˳а죬�й��ƶ������з�����Э��ġ�2017��ȫ��洢��ᡱ�ڱ��������Ƶ���С��ڻ����ϣ��Ƽ��㿪Դ��ҵ�����ں�������Ŀ���鳤���й���Ϣͨ���о�Ժ���ɲ�ʿ������Ŀ�飬�����ˡ��ں����ݰ�Ƥ���һ���֣��ں����ݴ洢����

���ɲ�ʿ��ʾ���ڴ�����ʱ����������ҵ���ݱ���ʽ����������ҵ����ת�����У���ҵ���ݴ�����������ḻ�����ݷ���Ҫ��Խ��Խ���Ӵ�ͳ�ı���������OLAP��OLTPҵ�����˵���������ʵʱ���ݷ���������ѧϰ���µ����ݷ���ģʽ���������ǣ���ͬ���ݴ����ܹ��Եײ����ݵĴ洢/��֯������(����)�����������ӿڶ������ͬҪ��һ��������Ҫ���������ײ�ͬ�ṹ�����ݼ������������������أ����ݲ��ܹ����������ƽ̨ά���ɱ����������������ת�����۵����վ����������谭�˴����ݷ���������Ӧ�úͷ�չ�����ں����ݴ洢ͨ��һ�����ݴ洢������ʵ�ֺ�����������(�����ﵽEB���ģ��������ݴ�����м������ϣ���������ά�ȴ��ά���ϵ�����)�Ĺ鲢����֧�ֶ�ά��������ϲ�ѯ�ͷ�����֧�ֶ��ֿ��ٲ�ѯ����(����˲�ѯ������ɨ�衢�굥��ѯ��)��ͳһ��Ӧ������Ч�����ҵ���¶�����ݴ洢�����⡣��ˣ��ں������Ǵ�����δ���ķ�չ����

���ɲ�ʿ�����˲�ͬ��ҵ���ں����ݴ洢�IJ�ͬ�����Լ�Ŀǰҵ����͵Ĵ�����ϵͳ�洢�������������ҵ�ں����ݴ洢����ʱ�ľ��Ͳ��㡣����������Apache������ORC��Parquet��CarbonData��Ϊ������Ŀǰҵ���������ںϴ洢��������Щ���������ļ����Աȣ��Լ���10�����ݹ�ģ�µĹ��˲�ѯ�����;ۺϼ��㳡���µ����ܶԱȡ�

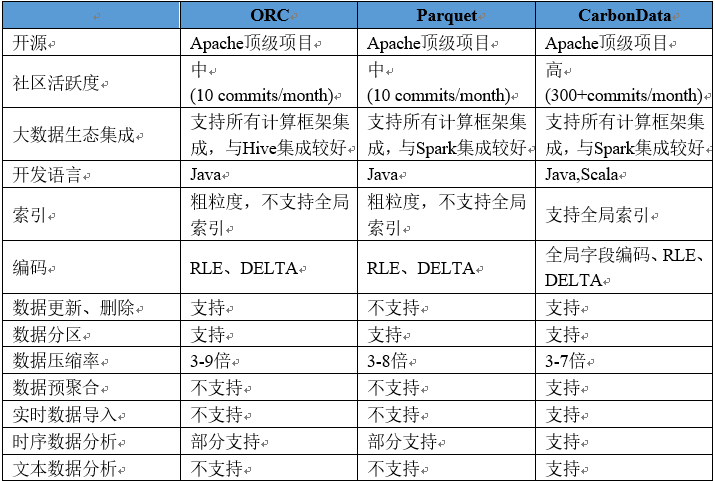
��1 ��Դ�ں����ݴ洢�������ԶԱ�
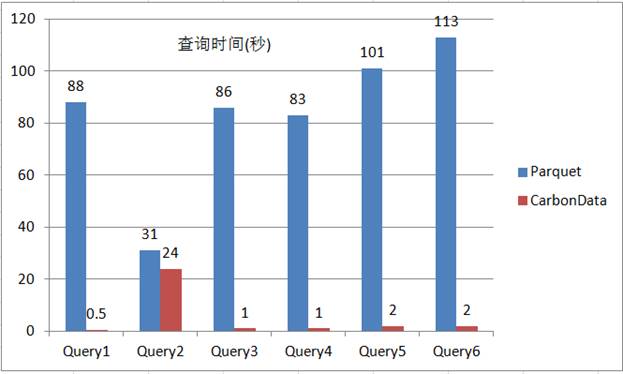
ͼ6 Parquet��CarbonData�ڹ��˲�ѯ�����µ����ܶԱ�
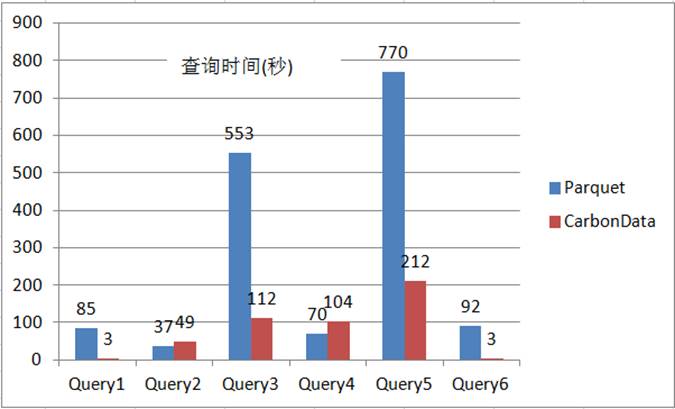
ͼ7 Parquet��CarbonData�ھۺϼ��㳡���µ����ܶԱ�
������ɲ�ʿҲ���ںϴ洢�����ķ�չ������չ����ϣ��һ�����û���ҵ�������뿪Դ�����Ļ��ͨ�����������볡�����ƶ��ں����ݴ洢������ҵ����ء���һ�������ò�ҵ��֯����չ������������ȳ��ϼ�ǿ���̼�Ĺ�ͨ���������ͬ�ٽ������ķ�չ��Ӧ��ˮƽ��������
Apache® CarbonData™���ܣ�
Apache® CarbonData™���ɻ�Ϊ��Դ���Ĵ����ݸ�Ч�洢��ʽ���������Apache® CarbonData™�������ƶ������ݿ�Դ�����ij�����չ����һ������ͬʱ�������ҵ���������Ч�����š�������̬�Ĵ��������ں����ִ洢������Ŀǰ��CarbonData�����Ѿ��ڻ�Ϊ��MRS������ʹ�á���Ϊ��MRS��������ȫ���ݿ�Դ����Ļ����ϣ��ں�CarbonData���ƣ�֧�ִ��ģ�����ݴ洢�������ͼ��㣬Ϊ�ͻ��ṩ��ʱ����ҵ��һվʽ�����ݷ�������ҵ���ɼ�Ԧ�������ݣ��������ݼ�ֵ�����̺���ռ���Ȼ���
����˽⻪Ϊ�ƴ洢��Ʒ��//www.huaweicloud.com/product/





������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼



























